
Google has disclosed the internal infrastructure powering its massive A/B testing operations across interconnected services worldwide. The system addresses a critical challenge: conducting reliable experiments when traffic flows through multiple infrastructure layers, user interfaces, and backend systems. By standardizing how experiments are distributed and measured, Google ensures teams can safely test changes while maintaining statistical accuracy and preventing conflicting tests.
The core problem this solves affects any large organization managing multiple related services. As experimentation becomes standard practice in product development, inconsistent task allocation, duplicate tests, and fragmented telemetry degrade data quality. Google’s approach centralizes experiment distribution and measurement across this complex web of services.
At its foundation sits a single distribution layer – the critical component determining how traffic gets allocated between experiments. This layer supports hierarchical distribution, allowing tests at different stack levels while reducing conflicts between overlapping experiments. Crucially, it ensures deterministic allocation: a specific user or session always receives the same variant assignment, preventing variant mixing and maintaining experimental stability over time.
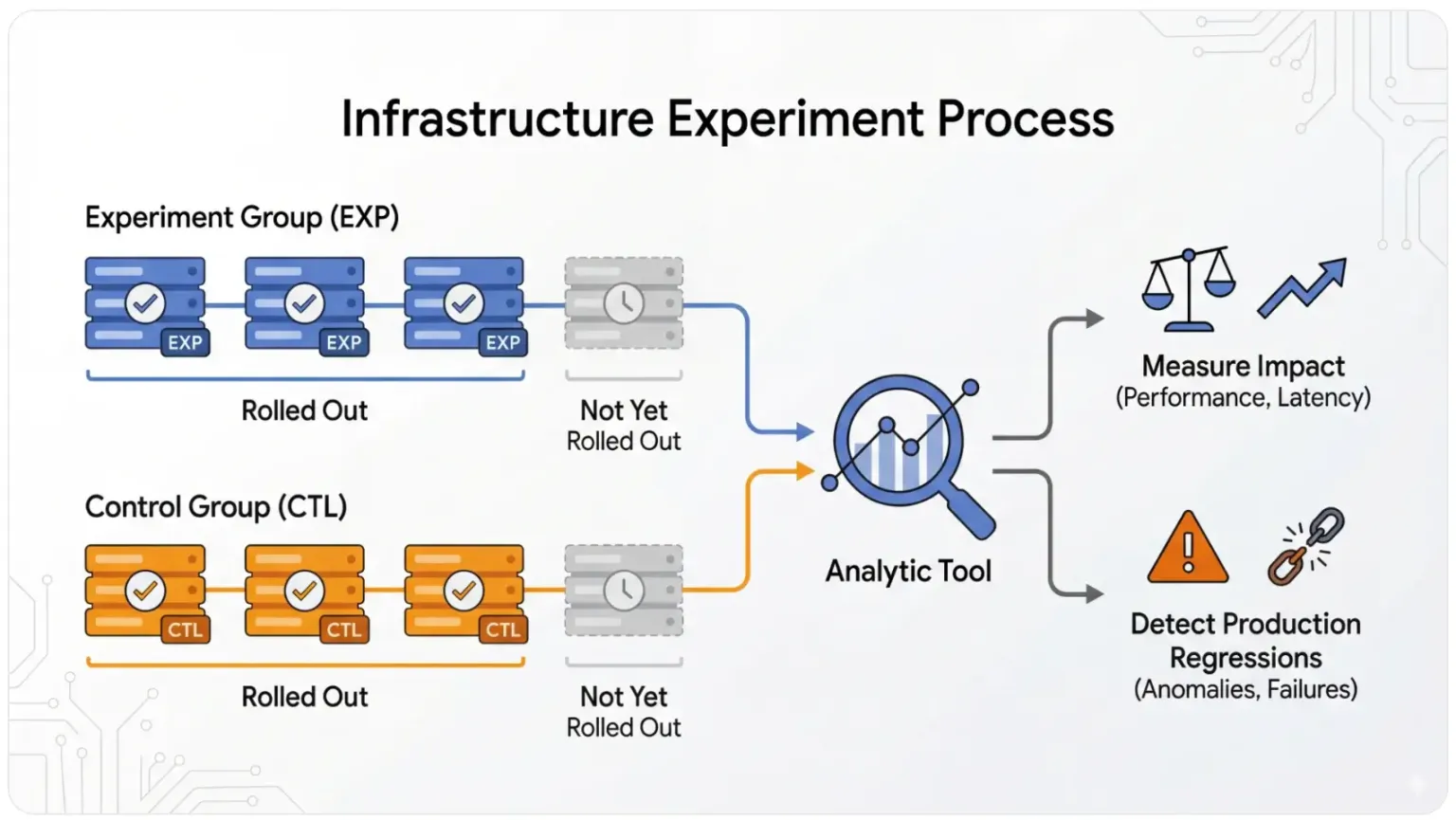
Rather than relying on isolated implementations for each product, Google employs shared infrastructure managing experiment configuration, assignment logic, and event logging. This guarantees consistent user distribution across experimental groups, even when those users interact with multiple services running different tests simultaneously.
Measurement accuracy depends on exposure logging – recording exactly when and how users encounter experimental treatments. This distinction between assigned and actually-exposed populations increases metric reliability. The system includes protective mechanisms preventing traffic limit violations or safety rule breaches during experiments.
Google emphasizes distributing experiment definitions throughout its infrastructure. Services evaluate experiment state locally rather than making centralized calls, reducing latency and dependency on central systems during real-time decision-making. This architecture supports high-performance environments requiring instantaneous decisions.
Anil Bhagavatula, vice president at digi edZe, captured the essence of this approach:
The takeaway is straightforward: infrastructure experimentation involves far more than code adjustments. It requires robust, statistically sound, and secure frameworks that treat data centers as laboratories.
Analytics pipelines tightly integrate with this experimentation infrastructure, aggregating results across services and enabling teams to measure impact throughout entire user journeys – not just within individual services. Standardizing both assignment and measurement reduces operational costs for product teams while accelerating iteration cycles. By consolidating experimentation primitives into shared infrastructure, Google aims to boost both speed and confidence in product decisions across its entire ecosystem.
